Split Data With Groups
Overview
Problem solved: create train/test splits that preserve class balance while preventing leakage across related samples such as patients, cases, or slides from the same specimen.
Use this example when:
- one biological unit contributes multiple samples,
- random splitting would leak information,
- and you still want class stratification.
Why This Approach
ratiopath.model_selection.train_test_split extends the familiar scikit-learn interface with group-aware splitting.
If you need repeated split generation instead of one split, use StratifiedGroupShuffleSplit directly.
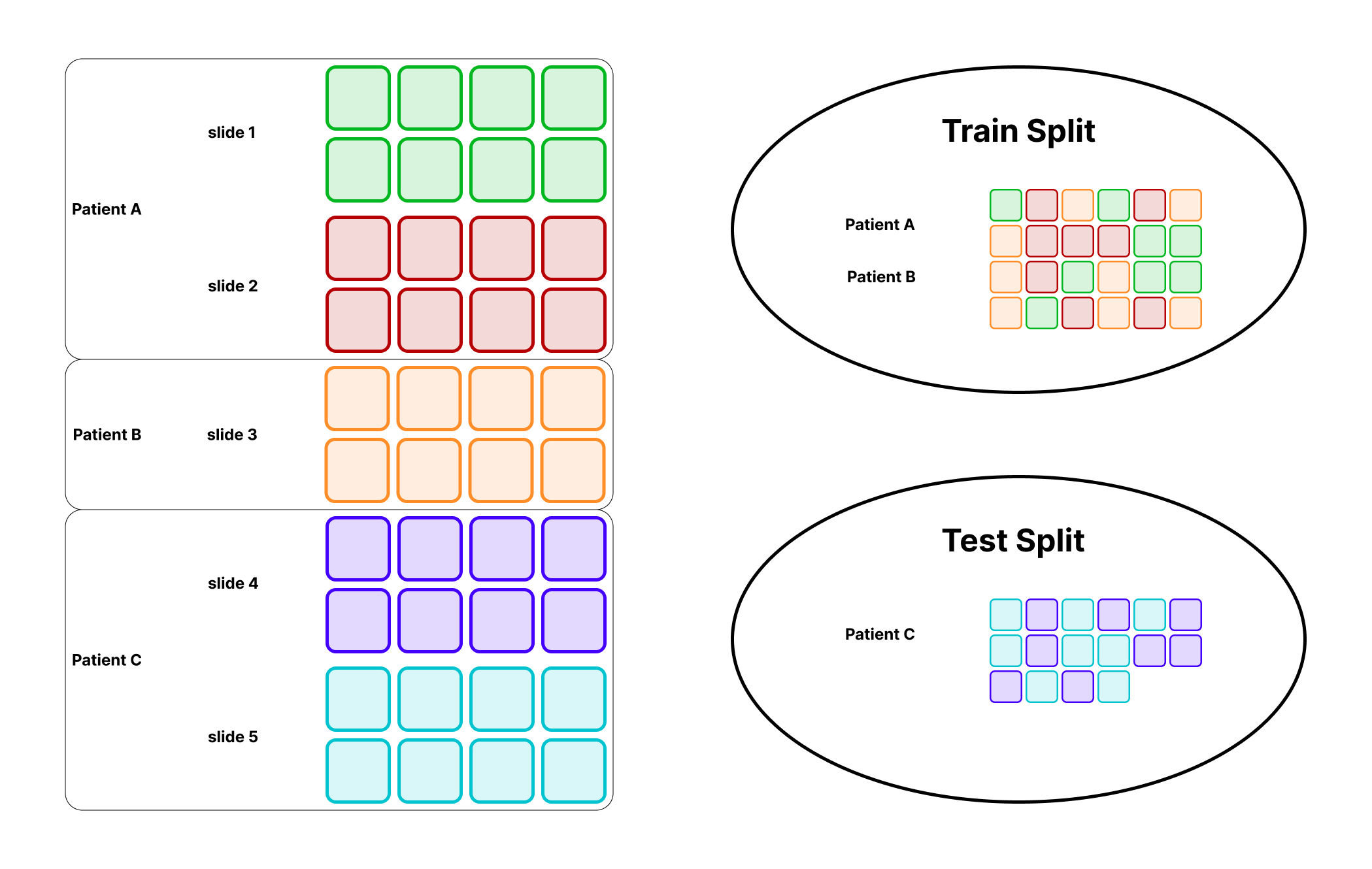 The important rule is simple: all slides and all tiles from one patient or case must stay on the same side of the split.
The important rule is simple: all slides and all tiles from one patient or case must stay on the same side of the split.
One-Shot Train/Test Split
import numpy as np
from ratiopath.model_selection import train_test_split
X = np.array(["tile_1", "tile_2", "tile_3", "tile_4", "tile_5", "tile_6"])
y = np.array([0, 0, 1, 1, 0, 1])
groups = np.array(["patient_a", "patient_a", "patient_b", "patient_b", "patient_c", "patient_c"])
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.33,
random_state=42,
stratify=y,
groups=groups,
)
Under the hood
ratiopath.model_selection.train_test_split mirrors the scikit-learn API, but switches splitter implementations depending on the constraints you provide.
- If you pass only
stratify, it behaves like a stratified shuffle split. - If you pass only
groups, it behaves like a group shuffle split. - If you pass both, it uses
StratifiedGroupShuffleSplit.
That last case is the key extension in this repo. The implementation repeatedly evaluates candidate group-respecting splits and chooses the one whose class distribution is closest to the global distribution. This is an approximation, but it is much safer for pathology data than naive random splitting because tiles from the same patient or case cannot leak across the boundary.
Repeated Splits For Evaluation
import numpy as np
from ratiopath.model_selection import StratifiedGroupShuffleSplit
X = np.arange(12).reshape(6, 2)
y = np.array([0, 0, 1, 1, 0, 1])
groups = np.array([1, 1, 2, 2, 3, 3])
splitter = StratifiedGroupShuffleSplit(n_splits=3, test_size=0.33, random_state=42)
for train_index, test_index in splitter.split(X, y, groups):
print(train_index, test_index)
Example output
[0 1 2 3] [4 5]
[2 3 4 5] [0 1]
[0 1 4 5] [2 3]
Why repeated group-aware splits matter
In pathology datasets, results can vary noticeably depending on which patients or slides land in the test set. Using repeated group-aware splits gives you a more stable view of performance than a single random partition.
This is especially useful when the number of groups is limited or the label distribution is imbalanced, because a single split can otherwise overstate or understate generalization quality.
When Not To Use Group-Aware Splitting
You do not need the group-aware path when:
- every row is independent,
- leakage between rows is not a concern,
- or there is no meaningful grouping variable to preserve.
Failure mode this avoids
Without grouping, tiles from the same specimen can appear in both training and test sets. The model then sees very similar morphology during training and evaluation, and measured performance becomes optimistic. The grouped splitter prevents that by moving the split decision up to the group level instead of the row level.